

2024
Fundamentals of library cataloguing workshop (online) 24 October, 2024 (LAI accredited workshop)
Are you new to cataloguing, or returning to it after a break? Join the LAICMG online on 24 October to dive into cataloguing today with Anne Welsh
Guided by trainer Anne Welsh (Beginning Cataloguing), we’ll consider first principles (what we are really doing when we catalogue); the language of cataloguing (basic jargon-busting); and subject analysis (the aboutness of the thing in our hands). In practical terms, we’ll create basic records (in a Word document or in our notebooks) for three related works, including FAST subject headings. We’ll also consider the tricky bits of some other books that have quirky but not uncommon elements affecting how we describe their title, extent, illustrations and inserts. We’ll look at how we make sure that the names of their creators are entered consistently (Name Authority control) and that they receive the correct subject headings (FAST).No knowledge of MARC or RDA is required (cheat sheets will be provided) and no pre-existing knowledge of how to catalogue is needed – if you can search your own catalogue, this training will provide you with the fundamentals to understand how the cataloguer decided what to put on the catalogue in the first place
Tickets can be booked on our eventbrite page and Library Association of Ireland members can avail of a special discount price (with a further discount for LAI student members) subsidised by the LAICMG. This course has been certified by the LAI Continuing Professional Development Committee. Attendees will receive an LAI CPD certificate which can be used to build their LAI portfolio.
About the trainer:
Anne Welsh has been cataloguing professionally since 1993 and teaching others to catalogue since 1995. She is the lead author of Practical Cataloguing : AACR, RDA and MARC21 (London: Facet; Chicago: Neal Schuman, 2012), a core text in iSchools internationally.
For more information see: beginningcataloguing.com Tickets are limited so don’t delay. We look forward to seeing you on the day.
LAI CMG AGM 2023 and Keynote on Diversifying Dewey: Changing the DDC23 to better represent Irish Travellers

Diversifying Dewey: Changing the DDC23 to better represent Irish Travellers
About this event
Following the recent successful proposal by the LAICMG to add a specific class number for Irish Travellers/Mincéirí to the Dewey Decimal Classification system, the project leaders, committee members Dean Waters (Assistant Librarian, Griffith College, Dublin) and Ruth O’Hara (Assistant Librarian, Maynooth University) will give a keynote describing the process involved in revising the Dewey Decimal System (DDC) to provide a more accurate and inclusive description of Irish Travellers.
Also known as Mincéirí, Irish Travellers are a distinctive ethnic community based primarily in Ireland. However, throughout their history they have experienced widespread discrimination, exclusion, and stereotyping. This fact was somewhat reflective in the DDC, as Irish Travellers were frequently misclassified. This case study examines the treatment of Irish Travellers, who were not specifically mentioned in previous editions of Dewey, prior to these changes. In addition, it looks at the steps taken by the LAI Cataloguing and Metadata group to prepare a successful exhibit which resulted in a new classification number specifically for this indigenous group. It argues that by working with key stakeholders, including Irish Traveller representative groups, library colleagues and academics, we can better guarantee access to accurate and relevant information for all library users.
This event will be held online. All LAI members are welcome to attend.
Date and time
Thursday, 18 April 2024, 16:30 – 17.00
Tickets are free of charge but numbers are limited. Please register on eventbrite here
Registered attendees will be emailed the Zoom link nearer to the date.
The talk will be followed by the LAICMG AGM also to be held online via Zoom.
2022
LAI CMG AGM 2021, keynote Isabelle Courtney (Media Literacy Ireland), tour of MoLI (February 2022)

The ongoing work of Media Literacy Ireland with key stakeholder the Library Association of Ireland and how LAICMG members can get involved.
About this event
The Library Association of Ireland Cataloguing and Metadata Group (LAICMG) are delighted to be hosting their 2021 AGM on 17 Feb 2022 in the gorgeous surroundings of the Museum of Literature, Ireland (MoLI ) preceded by a keynote by Isabelle Courtney on the topic of the ongoing work of Media Literacy Ireland (MLI).
Media Literacy Ireland is an informal alliance of organisations and individuals working together on a voluntary basis to promote media literacy in Ireland. The Library Association of Ireland (LAI) is a key stakeholder in this initiative and in her presentation, Isabel Courtney will outline the work to date and suggest ways in which LAICMG members can get involved.
Isabelle Courtney is a librarian and freelance journalist. She lectures in Records Management and Information Law on Library & Information Management MSc programme in Dublin Business School. She has a particular interest in Information and media literacy, knowledge and records management. She is passionate about libraries and has a love of the concept of lifelong learning and self-development. She is a member of the Library Association of Ireland (LAI) where she sits on the Career Development Group and Literacies Committee and facilitated the collaboration between the LAI and Media Literacy Ireland (MLI).
The keynote will be followed by an opportunity to network with refreshments and a complimentary tour of MoLI and the LAICMG AGM (members only)
Date and time
Thu, 17 Feb 2022, 16:00 GMT
Tickets are free of charge but numbers are limited. Please register on eventbrite here
Location
MoLI – Museum of Literature Ireland
86 Saint Stephen’s Green
D02 XY43 Dublin

Please note that, in line with government guidelines, all visitors must wear a face covering. All of the above arrangements are dependent on public health restrictions. The number of attendees will be limited to 25. Tickets are free and available on a first come first served basis
Schedule :
4:00 Registration,
4:15 Welcome;
4:30 Keynote;
5:00 Q&A
5:15 AGM;
5:30 Networking with refreshments and tour of MoLI

2021
LAICMG AGM 2020, hosted online by TCD Library

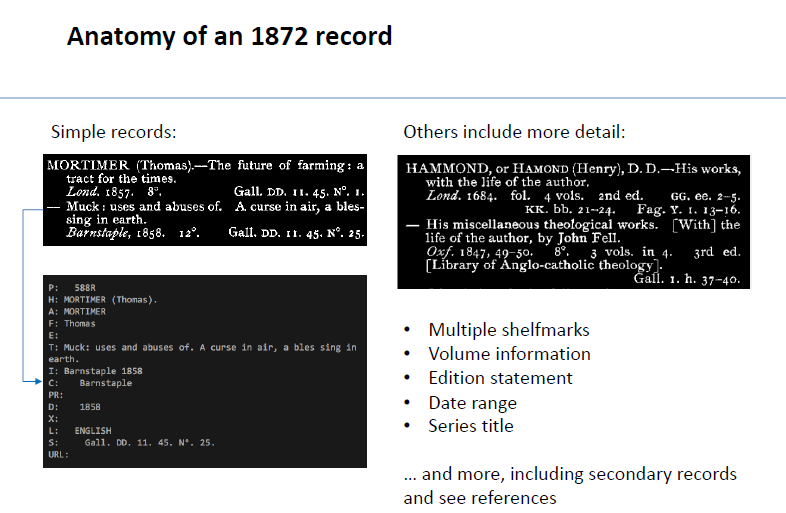
The LAI Cataloguing and Metadata Group’s AGM (2020) and networking event took place on 10th March, 2021 hosted virtually by TCD Library courtesy of the LAI Zoom account. This event featured a number of presentations on remote Cataloguing Projects during Lockdown at the Library of Trinity College Dublin and the 1872 Printed Catalogue Conversion Project.

Christoph Supprian-Schmidt (Acting Keeper, Collection Management), in his opening remarks outlined the situation for cataloguers during lockdown and explained how Library of Trinity College Dublin used the COVID-19 lockdown period to work on a range of remote cataloguing projects. He noted that at the one-year mark of the original lockdown, these projects will have added well over 200,000 records to Trinity’s main online catalogue, Stella Search with most records are coming from the 1872 Printed Catalogue Conversion Project – the focus of the presentations of the evening.
While the loading e-book records, cataloguing digital collections and the remote cataloguing of new books (from scanned title and key pages and other cataloguing data), continued, TCD Library also used this time to work on the 1872 printed catalogue conversion project. This work was facilitated by access to scanned pages (and OCR data) of legacy catalogues.
The TCD Library Printed Catalogue 1835-1887 by Trevor Peare, former Keeper (Readers’ Services)
Trevor Peare presented the historical background to the 1872 Printed Catalogue and its 40-year conversion project. James Henthorn Todd (1805-1869) was primarily responsible for the first TCD Library printed catalogue. Todd entered Trinity 1820, graduating with an honours degree in Science in 1824 followed by a Fellowship and ordination 1831. He was appointed Assistant Librarian 1834 and finding the existing catalogues inadequate, he began work on a new library catalogue in 1835. By 1846, the entire library had been re-catalogued., Todd was appointed Librarian in 1852 and the first volume of the printed catalogue was published in 1864. Todd died in June 1869 and Henry Hutton and Jan Hessels were appointed as editors 1872. The final volume of the nine-volume set was published in 1887. The edition of 250 copies included 48 Presentation Copies.

John Gabriel Byrne entered TCD in 1952 and graduated top of the class in engineering in 1956. He also studied French, Latin and Greek. He completed his PhD 1957 –1961 and began lecturing in 1963. He was appointed the first Chair of Computer Science in 1973 and became interested in the printed catalogue in 1985. He arranged to begin scanning of the original text in 1990 and the first database and search system 1993 was available in-house in TCD in 1993 and on the internet by 2005. The 5121 pages of one set of the eight volumes were separated in 1987 in order to make a microfiche copy and these pages, which were provided by Dr. Charles Benson, Keeper of Early Printed Books, were used to develop this on-line system. There are about 250,000 entries in the catalogue (including ‘see references’). The catalogue contains entries in at least eighteen languages. English and Latin occur most frequently and other languages in the Roman alphabet include French, Italian, Spanish, Portuguese, German, Dutch, Icelandic, Danish, Norwegian, Swedish, Welsh and Irish.
Dirty secrets of OCR, or, how to wrangle a big set of bibliographic legacy data by Joe Nankivell, Junior Bibliographer (Early Printed Books and Special Collections)
Joe Nankivell described the process of transforming the raw data from John Byrne’s OCR project into MARC records, with a particular focus on the data-cleaning side. The data had been shared on a memory stick that contained all Professor Byrne’s project files, including the records that formed the basis of his searchable online version of the printed catalogue. These records were distributed across over 5,000 files, one for each printed page, each containing between 30 and 50 records. The first task was to merge all these records into a single file where they could be manipulated in bulk, to impose consistency across the dataset prior to line-by-line proofreading by the wider team.
The OCR records had a superficial resemblance to rudimentary MARC records, with clearly identifiable bibliographic elements – a main heading (usually the author), the title, an imprint statement with place and date of publication, and a shelfmark. They could not be simply transformed and loaded, however, for three main reasons: Mapping difficulties due to inconsistent data structure, and more complex records that needed nuanced approach. OCR errors, as the original scans were low resolution. Missing data information not captured by OCR, or lacking in the original record.
The talk focused mostly on the first of these problems. One of the largest issues was how the 1872 catalogue handled multiple editions of the same title. These needed to be represented in MARC with an individual record for each edition, but in the printed catalogue they are filed under a single uniform title, usually reflecting the earliest edition held by TCD. This in turn appeared in the OCR data as a single record. Joe described the process of separating these out into new records using OpenRefine data-cleaning software, which proved to be the ideal tool for working with such a large and complex dataset.
Some of the OCR errors could also be identified and cleaned at the batch-edit stage, as they followed predictable patterns. And the data was further enriched at this stage by separating the imprint out into fresh fields for place and date of publication, as well as printer, series, date range, language, and other information that was available in some of the more detailed records. This allowed the creation of more technically precise MARC records, populating fields for country, language and date.
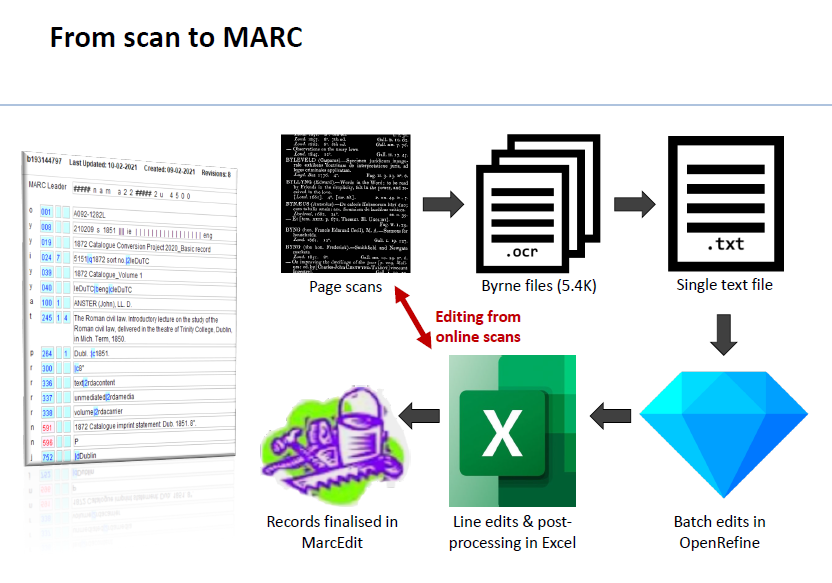
With the batch edits complete by the end of April, the dataset was shared among colleagues from across TCD Library, who painstakingly compared each line of the data with all 5,121 pages of the printed catalogue. This work went on over the rest of the year, and was finally complete just before Christmas 2020. In the final phase, the proofread data was given its final integrity checks and further augmented by Niamh Harte, the project manager who converted the records into MARC format and loaded them into TCD’s live online catalogue one volume at a time. All the presenters paid tribute to the work of their TCD colleagues Niamh Harte, Barbara McDonald and John Byrne on this project.
*Special thanks to Joe Nankivell for his help in summarising his work on data-wrangling and OCR for this blogpost.
2020
CMG AGM 2019, at the Irish Traditional Music Archive

On 6th February, 2020, the LAICMG held their AGM in the Irish Traditional Music Archive’s premises in Merrion Square. This was preceded by a talk on the ITMA’s linked data journey by Treasa Harkin of the ITMA.
Treasa began by explaining the ITMA‘s background and mission. The ITMA is a national public archive and resource centre for everyone with an interest in the traditional art forms of song, music, dance. The ITMA was established as a pilot project in 1987 by Harry Bradshaw and Nicholas Carolan, and has grown since then to become the trusted national repository for Irish music, song and dance. It has the largest collection in existence of the contemporary and historical materials relating to this subject.
The ITMA has four aims:
- To collect all the significant materials of Irish traditional music.
- To preserve the materials we collect indefinitely for present use and for future generations.
- To organise the materials and information in our collection and make them retrievable.
- To disseminate its materials or to make its materials and information as widely available as possible.
The LITMUS project was established to improve searching and access to web-based Irish traditional instrumental music, song, & dance resources; to improve semantic web-based descriptions of Irish traditional music; to advance research in this area and to increase audience’s understanding of Irish Traditional Music and the nature of oral traditions. LITMUS facilitates improved semantic web-based descriptions of, and access to, Irish music & dance materials such as those found in the ITMA; further applied & theoretical research in music information access, the semantic web, & cultural heritage informatics; and increases wider audiences’ understanding of Irish traditional music & unique considerations for orally-based music traditions in both non-academic & academic sectors. The LITMUS Project was granted €178,000 from EU for a two year programme and was delivered on time and on budget. The work was carried out by Dr Lynnsey Weissenberger, Marie Curie fellow, librarian and traditional musician.
Outputs of LITMUS
Extension of FRBRoo = Functional Requirements for Bibliographic Records +International Council for Museums – #International Committee on Documentation. Creating the ontology is the hardest part, which has been done. FRBR was designed for bibliographic material, CIDOC-CRM was designed for museum material, FRBRoo is a combination of both of those. Each item contains links, retrieving all the information about that item on ITMA’s LMS, website and digital repository. The authority files behind the links are freely available online. The ITMA is the trusted resource for authority records. Treasa concluded her talk by explaining that the holy grail has always been to develop a system that you could:
- query by playing
- distinguish between the different versions of tunes
The Linked Open Data project that is LITMUS and the online resources available in the ITMA will allow that to happen. Further information on the LITMUS project is available at here
2019
Tour of the National Botanic Gardens and Library

On the 18th July, 2019 the CMG annual summer visit or tour was held at the National Botanic Gardens of Ireland, Glasnevin. The group was treated to a very enjoyable guided tour of the gardens. This was followed by the visit to the Gardens’ specialist library, where librarian Alexandra Caccamo gave a short talk and showed the group a selection of some of the beautifully illustrated botanical books and materials held in the library of the Botanic Gardens.

Dewey Decimal Classification numbers for Gaelic Games
The CMG’s biggest news story in 2019 was the addition of classification numbers for Gaelic Games to the Dewey Decimal Classification system. Approved by the Dewey Editorial Policy Committee in September, 2019 and spearheaded by Mary Kiely, Cataloguing & Acquisitions Librarian at Dublin City University on behalf of the committee of the LAICMG, it followed months of hard work by members, collating lists of publications to establish sound ‘literary warranty’ and putting together a solid proposal. Dewey already had placeholders for Gaelic Games and its sports, but full, specific numbers had not yet been assigned. So the proposal was rather complex, but in short, the new numbers are:
796.337 Gaelic football

Details about the changes, as well as the process of making the proposal, can be found on the Dewey blog of 15 October 2019
CMG AGM 2018, at the National Library of Ireland
On 5 March 2019, the late Professor Richard Sharpe (Professor of Diplomatic at the University of Oxford), delivered the keynote address to the Library Association of Ireland Cataloguing and Metadata Group’s Annual General Meeting in the National Library of Ireland. He presented an overview of the Clóliosta catalogue project and where he requested the assistance of cataloguers and librarians in order to alert the editors to the existence of little-known or obscure copies and editions.
Copies of the draft Clóliosta were made available to curators in libraries with relevant Irish holdings The level of detail provided in the Clóliosta renders it an invaluable resource to cataloguers of Irish language publications who wish to add scholarly notes to records, including identification of typefaces and printing houses, and to those researchers interested in the book history and the history of print culture in the Irish language.
The Clóliosta is published by the Dublin Institute of Advanced Studies and is available to purchase from the DIAS website here

2018
Cataloguing and Organisation of Special Collections: a LAI RBG/CMG workshop
Organised by the LAICMG and the LAIRBG. 23 March 2018. Venue: Royal Irish Academy
Programme:
Morning Session – Case Studies. Opening remarks – Christoph Schmidt-Supprian, Chair Cataloguing & Metadata Group. Chair: Evelyn Flanagan, Special Collections Librarian, UCD
- Josie Caplehorne: Kent University partnership project with Rochester Cathedral
- John McManus, TCD Terry Pratchett collection
- David Meehan, DCU pamphlet collection
Afternoon Session – Panel & Audience Discussion
- Chair: Amber Cushing, Assistant Prof., School of Information Communication Studies, UCD.
- Panellists: Josie Caplehorne (Kent U), Evelyn Flanagan (UCD), Marian Keyes (DLR Lexicon), John McManus (TCD), David Meehan (DCU), Hugh Murphy (MU)
CMG AGM 2017 at the National Library of Ireland

The 2017 AGM of the LAI CMG took place in the National Library of Ireland on Wednesday January 31st, 2018 at 6 pm.
The AGM was preceded by a keynote address from John McDonough, National Archivist, on the topic of the “Beyond 2022” Project: Ireland’s National Memory .
“Beyond 2022” Project: Ireland’s National Memory
On 30 June 1922 the Treasury Room containing Ireland’s documentary heritage dating back to the thirteenth century was destroyed in a cataclysmic explosion and fire at the Four Courts. On the centenary of that blaze in 2022, this project will launch a Virtual Record Treasury that reconstructs the nation’s archives and its collective memories.
Beyond 2022 is an all-island and international collaboration. In partnership with the National Archives of Ireland and other national and international institutions, Beyond 2022 seeks to ensure a lasting and inspirational legacy beyond the current decade of centenaries. Working together, a Virtual Record Treasury for Irish history will be launched —an open-access, virtual reconstruction of the Record Treasury destroyed in 1922.
The Virtual Record Treasury
The centrepiece of the project is new an online resource — the Virtual Record Treasury — which will provide a digital reconstruction of the Record Treasury of the Public Record Office of Ireland as it existed in 1922, on the eve of the fire. This will become not only an essential platform for academic research but also a public resource with global reach and impact among the Irish at home and abroad.
The Virtual Record Treasury will provide:
- Data visualizations enabling researchers to explore the treasury of the Public Record Office and its collections
- A complete inventory of loss and survival from the 1922 fire.
- Digitizations of the surviving originals, transcripts and calendars.
- Detailed guides to the significance of those collections from the thirteenth century to the Victorian era.
- A vital hub linking replacement material held in archival repositories in Ireland and across the world.
Associated researchers: Peter Crooks, David Dickson, Shay Lawless, Micheál Ó Siochrú, Ciarán Wallace.
Other past events organised by LAIMG include:
(still a work in progress..)
2017
CMG training event: MarcEdit and OpenRefine.
3 November 2017 Venue: Dublin Business School
Owen Stephens delivered a workshop on MarcEdit and OpenRefine which should be of interest to cataloguers, repository managers and systems librarians. These popular tools are used to create and modify metadata and can be used by staff working with a range of library systems and repository solutions.
For more details see:
http://marcedit.reeset.net/ http://openrefine.org/
- This training teaches how to effectively work with batch loads of marc records, improve your productivity and increase your practical problem solving abilities.
- MarcEdit is a free piece of software which provides a suite of tools for working with marc records.
- OpenRefine (formerly Google Refine) is a powerful tool for working with messy data: cleaning it; transforming it from one format into another; and extending it with web services and external data.
- Owen has a useful series of five posts on his blog which go through a ‘worked example of fixing problem MARC data’ which you can check out here.
About Owen Stephens
Owen Stephens has been working in Library and IT services within the Higher Education sector for over 15 years. As well as a strong technical background, Owen has been on the management team of the library services of two leading UK Universities (Royal Holloway, University of London and Imperial College London), and he has been responsible for a number of innovative projects at both institutional and national levels. Owen has been working with linked data since 2008 including creating and publishing linked data at the Open University, delivering training on linked data at the British Library and building small software tools to work with and exploit linked data. He blogs at http://www.meanboyfriend.com/overdue_ideas/.
Benefits of this training
- MarcEdit and OpenRefine are two tools which increase your productivity when working with metadata.
- They allow you to make changes to a number of records at once and can be used to source, fix and enrich metadata.
- They work on a range of operating systems and compliment any Library Management System or repository solution.
- Knowing how to use them will improve your work and increase the value that you contribute at work.
2016
CMG AGM 2016 and ‘When Cataloguing Becomes Metadata’ by Jenny O’Neill (Data Manager, UCD Library Research Services)
23 November, 2016. Venue: National Library of Ireland
The CMG AGM encapsulated a networking event which included opening remarks by the LAI President, Philip Cohen, with warm words of encouragement, followed by a talk from Jenny O’Neill (metadata librarian, UCD), who traced in her keynote address the evolution and value of cataloguing through an engaging reflection on her own career and hobbies.
Abstract: “to look at the evolution of resource description from ‘traditional cataloguing’ for describing bibliographic resources to the emergence of metadata to describe digital resources. While these two things are very different they share the common goals of consistent and accurate descriptive metadata to aid discovery of the resources. … user generated metadata for research data and how librarians can help influence better metadata not just in the Humanitites and Social Sciences where I suspect we feel most comfortable but also in the so called ‘hard sciences’.”
LCSH and FAST Training
19th and 20th of May 2016 Venue: Dublin Institute of Technology
On 19th and 20th of May, the LAICMG held a double-workshop on subject indexing, specifically Library of Congress Subject Headings (LCSH) and Facet Application of Subject Terminology (FAST) (the latest mutation of LCSH). It took place in DIT Aungier Street (another new departure), and we were lucky to get veteran trainer Keith Tricky for his last teaching engagement – he had officially retired from training in April and we received very positive feedback from attendees afterwards.
Description:
- A description and full itinerary for the LCSH training on the 19th of May can be found here.*
- A description and full itinerary for the FAST training on the 20th of May can be found here.*
2015
LAICMG AGM 2015 and ‘Report on the implementation of RDA in Irish libraries’ by Marie Cullen (Maynooth University Library)
20 November 2015. Venue: Berkeley Library, TCD
The first winner of the LAICMG bursary, Marie Cullen, presented an RDA update at the 2015 CMG AGM which followed her presentation at the first annual CONUL in Athlone at the beginning of June. This was a very appropriate and well received airing of the research since it was based on a survey of CONUL members.
Introduction to RDA with Keith Trickey
Organised by LAICMG and LAI Western Regional Section. 24 September 2015 Venue: Glucksman Library, University of Limerick.
This workshop provided a brief introduction to RDA, to establish the identity of the new approach to matters bibliographic then examine the modifications made to MARC 21 to accommodate these changes. The focus was on RDA type 1 Entities (Work, Expression, Manifestation, Item) and MARC 21 Bibliographic format.
The aim of the course is that by the end participants would:
- Be aware of the principles underpinning RDA
- Have explored the use of RDA to describe both items
- Understand the continuing development of RDA
- Be able to assess the potential impact of RDA on their information service.
- Recognises the RDA changes in downloaded MARC 21 records
- Implement appropriate RDA areas in MARC 21
A full course outline is available here.
2014
CMG AGM 2014 and Linked Data for Libraries
Organised by LAICMG and the Digital Repository of Ireland,6 November 2014, Trinity Long Room Hub , TCD
Outline
Linked Data: is this just a techie buzzword? Does it have any relevance to libraries? Will it transform library catalogues and cataloguing activities as we know them?
In general, the aims of the seminar were as follows:
- To contextualise and explain what linked data is
- To demonstrate how existing bibliographic data can be converted into linked data
- To show how linked data can be integrated into cataloguing workflows
Programme
- Introduction to linked data / Christophe Debruyne
- Real linked data: publishing and using it / Owen Stephens
- Publishing the British National Bibliography as linked open data / Corine Deliot
- Irish Record Linkage Project / Dr. Brian Gurrin and Dolores Grant
- MARC and BIBFRAME / Tom Meehan
Introduction to Persons, Families and Corporate Bodies in RDA
Organised by LAICMG and the Digital Repository of Ireland . 13 June 2014 Venue: UCD Health Sciences Centre
This workshop provided an introduction to RDA Type 2 Entities (Persons, Families and Corporate Bodies), and then examined the modifications made to MARC 21 Authority Format to accommodate these changes.
The aim of the course is that by the end participants would:
- Be aware of the principles underpinning the description of RDA Type 2 entities
- Have explored the use of RDA to describe Persons, Families and Corporate Bodies
- Understand the continuing development of RDA
- Be able to assess the potential impact of RDA on their information service.
- Recognises the RDA changes in downloaded MARC 21 Authority records
- Implement appropriate RDA areas in MARC 21 Authority format
Introduction to RDA
Organised by LAICMG and the Digital Repository of Ireland. 12 June 2014 Venue: UCD Health Sciences Centre
This workshop provided a brief introduction to RDA, to establish the identity of the new approach to matters bibliographic then examined the modifications made to MARC 21 to accommodate these changes. The focus was on MARC 21 Bibliographic.
The aim of the course was that by the end of the course participants would:
- Be aware of the principles underpinning RDA
- Have explored the use of RDA to describe both items
- Understand the continuing development of RDA
- Be able to assess the potential impact of RDA on their information service.
- Recognises the RDA changes in downloaded MARC 21 records
- Implement appropriate RDA areas in MARC 21
A full course outline is available here.
2013
CMG AGM 2013 and Annual Seminar : Whatever Happened to Classification?
Organised by LAICMG and the Digital Repository of Ireland. 8 November 2013. Venue: National Library of Ireland
Programme
- Classification at the British Library: partnerships, projects and perseverance / Caroline Kent
- There’s nowt queer as folk … music: classification at the Irish Traditional Music Archive / Grace Toland
- Constructing a thesaurus of Irish folklore using facet analysis/ Catherine Ryan, DRI
- Linked Logainm: a source for library metadata? / Eoin Ó Carragáin, NLI
- Q&A with mid-morning speakers
- Classification with QR codes / Robert Reid, Highland Libraries
- Image indexing with the Getty Vocabularies and ICONCLASS / Marta Bustillo, NCAD
- AGM
